
A super fast thresholding technique
In computer vision, thresholding is probably the most basic operation. It needs to go through every single pixel of every single frame to detect objects. If you can make it efficient, you'll have CPU time to do other stuff. Today (after a long time, I might add) I'll introduce you to an interesting technique that can reduce the number of operations per pixel.
The standard way
The usual way to go about thresholding would be to check if the values in each channel are within a certain range or not. Psuedo code for this would look like:
if (redcomponent > somevalue1 && redcomponent < somevalue2 && greencomponent > somevalue3 && greencomponent < somevalue4 && bluecomponent > somevalue5 && bluecomponent < somevalue6) { // Do something (like mark it as white) }
The problem with this is, it takes six comparisons - too much. Another problem is the extensive branching it does. The branching messes up pipelined processors. Not good.
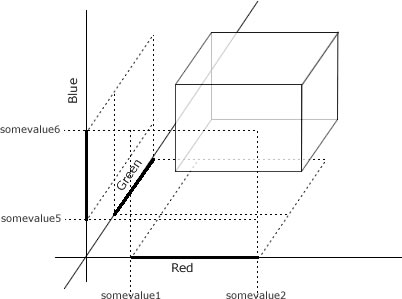
Thresholding with the RGB space
The new technique
The problem with the previous approach is that it uses two comparison for every channel. But these comparisons are always constant - for red, it's always from somevalue1 to somevalue2. So here's the key idea:
We can create an array or table of 256 elements. Set values in the range somevalue1 to somevalue2 to 1 and everything else to zero. Similarly, create two more arrays for green and blue.
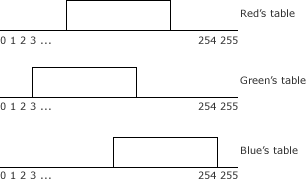
The tables created for red, green and blue
Now, to check if a certain pixel should be marked white or not, we could use the following pseudocode:
if(table_red[redcomponent] && table_green[greencomponent] && table_blue[bluecomonent]) { // do something }
If redcomponent is a value between somevalue1 and somevalue2, the table will contain a 1. Otherwise a zero. Similarly for other channels. If the color lies in the correct range, the condition evaluates to true. And you know you need to mark this pixel as white (or whatever you want to do)!
Simple, isn't it? You're trading a bit of memory for an increase in speed.
You don't need to write code for this little technique. OpenCV (and most other vision packages) use exactly this for thresholding. They even use specialized processor instructions to make it go faster.
Parallel thresholding
Here's an interesting idea presented in the paper (find it below). Let's say the tables you make are arrays integer type. You're only storing a '1' to mark if a certain value can be accepted.
The '1' is just a single bit. You have 31 extra bits (on 32 bit machines). You could use those bits to store a '1' for other colors. So the first bit could correspond to a yellowish shade, the second to a bluish shade, the third to an orangish shade, etc. Then, the result of the and'ing would be a 32 bit integer. Its first bit is '1' if the color is yellowish. The second bit is '1' if the color is bluish. The third bit would be '1' if the color is orangish.
In this example, both the first and third bits can be '1' simultaneously. This indicates that the color belongs to two classes - orange and yellow! Based on this, you could set the pixel to white in two different images (one for yellow and one for orange).
This way, you can do up to 32 colors simultaneously. That's a LOT of colors!
You'll probably need to write code for this - you'll have to decide which bit corresponds to which color.
Experimental results
I did a quick test to verify the paper - I used a custom function that takes an image, goes through each pixel, does the 6 comparisons and marks the pixels as foreground if necessary. Competing against this function was the standard threshold function of OpenCV.
Thanks for Shervin Emami for the timing macros! You might find them useful as well.
The results were obvious:
| Image size (pixels) | Standard (ms) | Super fast method (ms) |
|---|---|---|
| 73902 | 1.278624 | 0.394651 |
| 636000 | 5.791450 | 2.213925 |
| 1555200 | 13.664513 | 5.687084 |
That is an almost 300% increase in speed. I did ignore the fact that you can use SIMD instructions to speed it up further. But a 3x increase in speed has way more weightage!
Related posts



The Sobel and Laplacian Edge Detectors
Edge detection is a fundamental image processing operation. Learn about how to calculate derivatives and find edges in your images using simple matrix operations.
Read more
